DB-Engines Ranking被全球数据库人士频繁引用,同时也被当成是最权威的数据库流行度排名榜单之一。我想这个权威可能来自于几个因素。第一历史悠久,DB-Engines 2012年开始排榜,每月更新。第二数据比较全面。
今天我想对DB-Engines Ranging做个小的质疑。主要是两个原因,第一、这个榜单排名算法没有公开。只给了一个模糊的说明。对一切黑箱的东西,都是可以质疑一下的。第二、排名结果跟直观感受不一致。
排名算法不公开
这个排行榜的全称是数据库流行度排行榜, Popularity Ranking。根据DB-Engines的模糊说明,目前主要考虑了:
- 数据库在Google和Bing中提及到次数。
- 作为大众感兴趣程度的体现,引入了Google Trends中某数据库被搜索的次数。
- 技术论坛Stack Overflow和DBA Stack Exchange中被问到和回答的次数。
- 在Simply Hire和Indeed中招聘岗位中提及的次数。
- 在Linkedin中作为专业人士档案技能提及到的次数。
- 在Twitter中被提及到次数。
其中没有包含安装量。作为衡量流行度Popularity,以上的说明中包含的因素,除了对移动互联网考虑不足以及数据源比较偏美国的之外,总体上来说还是可以的。之所以说这是个模糊的说明,主要是其中既没有各个数据源的权重说明,也没有数据时间范围的说明,是任意时间段还是最近若干年等。
排名结果与直观印象不符
我们看一下最近2022年6月的关系型数据库排名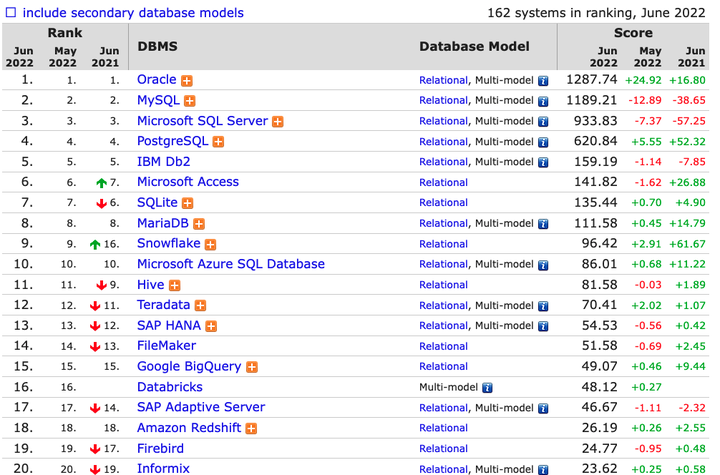
我们注意到Oracle的分数是最近快速蹿升大红大紫的Snowflake的13倍,是第16名Spark的26倍。这跟你的直观印象一致吗?每1个人关注databricks,就有26个人关注Oracle?每问一个TiDB相关的问题,就有 400 个Oracle的问题问出?
Oracle的分数可能被高估了
鸟瞰一下数据
时间有限,没有爬说明中的所有网站,而是选了同类的代表。选了Google,Google Trends,Stack Overflow,Simply Hire,没有看twiter。数据做了同比例缩放。因为这是Populairty,明确选择了12个月内的数据,而不是所有时间段,这样免去一些产品的 legacy 误差。
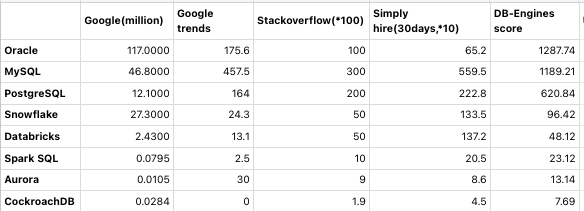
图中根据DB-Engines的分值从高到低,选择了款老中青三代数据库。画个曲线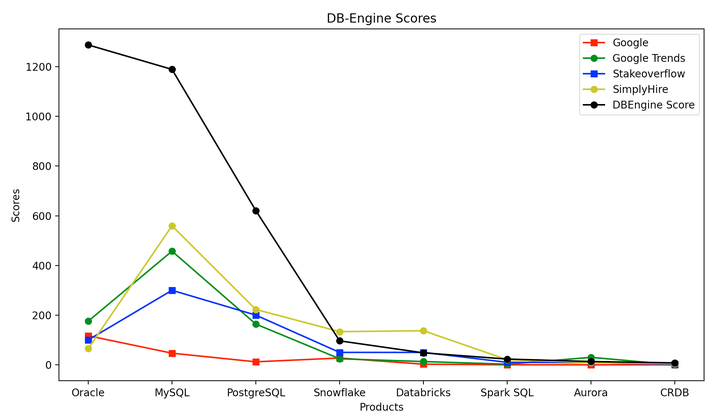
首先奇怪的是MySQL除了Google得分比Oracle低,其他得分都大幅领先Oracle,最后得分反而比Oracle低很多。为什么?
多元线性回归
网上抄两句Python代码,回归推算一下每个维度的权重。
filename=’dbeng.csv’
df = pd.read_csv(filename)
x = np.array(df.iloc[:,1:5].values)
y = np.array(df.iloc[:,5].values)
cft = linear_model.LinearRegression()
cft.fit(x,y)
print(“model coeeficients”,cft.coef_)
print(“model intercept”,cft.intercept_)
结果
model coeeficients [ 6.52852337 1.79811976 2.92829948 -1.45595674]
model intercept -5.20967181788734
也就是说为了回归出目前DB-Engines的分数,Simply Hire的权重变成负值了。这个显然是错误的。Simply Hire 标志着该数据库相关岗位,初步估计与Stack Over Flow 类似重要,拍脑袋给个 1.0 的权重。那么公式变为:
DB-Engines score = 6.52852337\times Google + 1.79811976\times Google Trends + 2.92829948\times Stack Overflow +1 \times Simply Hire
新的排名(^-^)
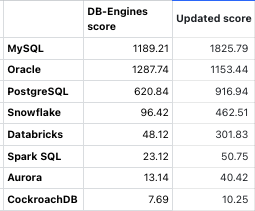
新的排名根据更新过的公式
看我们自己也可以做个排名算法了^-^。 而且跟直观印象更加一致。比如,MySQL的Popularity显然高于Oracle,不然开源做了这么多年,开源更容易被大量的用户采用以及更多的从业人员的优势哪里去了?Oracle的流行度大概是Snowflake的2倍, Databricks的3倍更加符合目前的常识。